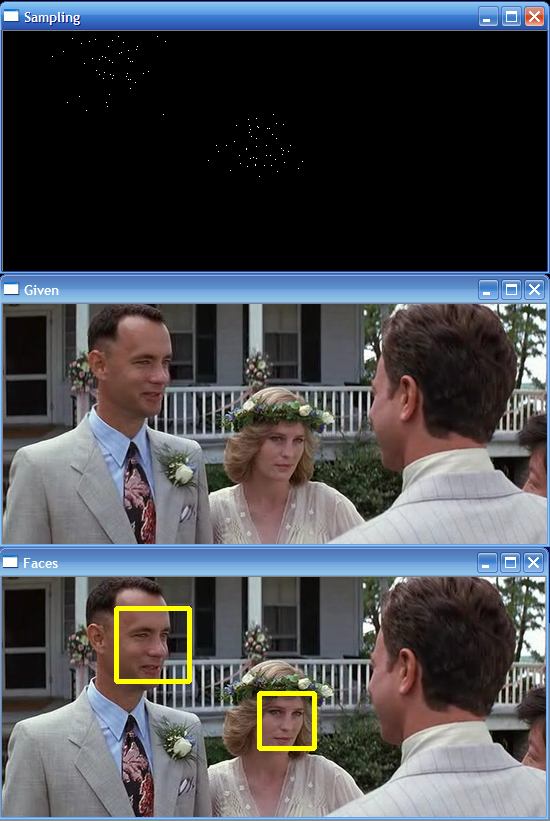
| Sampling: In particle filtering, samples are
drawn according to a motion model. My motion model predicts the
location of the upper-left corner of the box containing the
face according to constant velocity and gaussian noise with a
standard deviation of 0.2 times the dimensions of the box (so a
box that is wider than it is tall will have a greater st.dev.
in X than in Y). This image shows sampled positions for two
faces, the samples are drawn so the likelihood of drawing a
sample from any given location is proportional to the gaussian
weight at that location:
Calculating Weight / Likelihood: When a
face is first detected, I calculate an RGB histogram to
represent that face. In each channel, the histogram has 64
bins, each bin spanning 4 values of the scale from 0 to 255.
When tracking, after sampling according to my motion model
in X,Y space, I extract an image region with the same width and
height of the face I am tracking at each of the sample points
(the point is the location of the upper left corner). I then
calculate an RGB histogram for each sample the same way, then
correlate the histograms for each channel in the sample with
those that I built for the face when it was first detected, let
these be called rCorr, gCorr, and bCorr. Then:
similarity = (rCorr*0.4 + gCorr*0.3 + bCorr*0.3); // a
weighted sum placing slightly more importance on red (since
faces are mostly red)
weight = pow(2.718281828, -16.0 * (1-similarity)); // the
weight of a sample is given according to a curve that makes
weight drop off steeply as similarity decreases
For some of my results, I simply performed sampling once and
moved the updated face to the sample with highest weight, which
worked ok but tended to jitter and wiggle a lot.
Sequential Importance Resampling: It is
important in particle filtering to resample according to the
weights that you found at each point in the last round of
sampling.
For example, imagine you are trying to find a something
green and you have 5 samples:
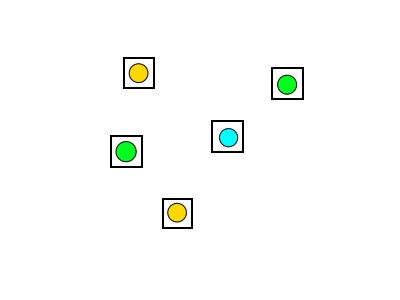
Those containing a green dot would probably have very high
weight and those with other colors would have a low weight. To
find higher concentrations of green, we want to resample around
the better previous samples. We do this by drawing new samples
according to a cumulative distribution of weights on the
previous samples:
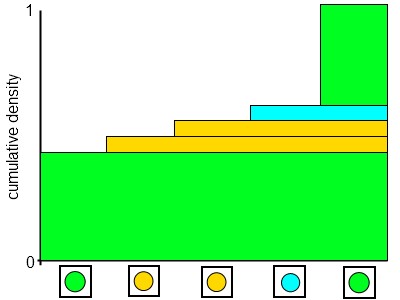
The figure above can help visualize the resampling process.
The height of the bar for a given sample indicates the
likelihood of a resample being performed there. Lots of
resamples are taken, and drawing them according to this
distribution results in the resamples being clustered around
the better samples from the previous frame. In my results, when
I resample I identify the previous sample I am working on, then
add gaussian noise with a standard deviation of 0.1 times the
box dimensions. This is lower than the st.dev. used in the
first sampling on a new frame because the resampling can be
clustered more tightly to refine better.
Resampling can be performed many times, each time working on
the weights and samples from the last round of resampling. I
find that 3 rounds of resampling achieves very good results and
eliminates a lot of the wiggling from when resampling was not
performed.
Dimensionality: Particle filtering is meant
to find optimal values in a high dimensional space. For most of
my results, I sample in X,Y space, but I also tried sampling in
X,Y,W,H space (allowing the width and height of the box to
change). This worked well on a video occasionally, but often
proved unstable and shrank the box for the face too small -
finding tiny rectangular regions that happen to match the RGB
histogram for the detected face very well. This could be
mitigated by using a better similarity score than histogram
correlation, such as NCC of scaled images. However, this would
take longer to compute and may reduce the framerate at which
the tracking can run.
|